
PressW specializes in building AI solutions tailored to the needs of our industry partners. One of the most effective ways we demonstrate the value added to our client is by dispatching weekly updates communicating the progress made and the next steps on their project. These short-term updates are followed by a monthly progress report that highlights our contributions throughout the week.
However, due to the breadth of detail covered as well as our rigorous review process, crafting all monthly updates takes our engineers on average 10-15 hours during the last week of the month. This timeframe typically coincides with several client deadlines and the 10 hours could be better served by the PressW team using that time to actually code.
Given the strength of modern LLMs in summarizing large pieces of information, we ideated and built an automated LLM-backed report creation service, which is pipelined into 3 primary stages:
Notion Fetcher: The service fetches 4+ weekly updates for a particular month and progress report for the previous month via the Notion API from the client’s home portal in Notion and downgrades it to markdown text.
Update Writer Chain: The service then feeds the weekly updates, the past progress report and a pre-determined Notion template to a LLM chain which outlines a report and stitches together details, images, links, and callouts summarizing the weekly updates. This chain has been prompt-engineered to prevent hallucinations (preventing generation of fake data) and to be moderately deterministic. As of May 2024, we are using OpenAI’s GPT-4o as our LLM.
Notion Uploader: The service first takes the markdown text generated by the LLM chain, runs it through an HTML parser and converts each section of the tagged text to Notion blocks, a json-like format. These Notion blocks are then uploaded to a staging database where a PressW member can review the report before publishing it to each client.
This entire service is deployed via a Google Cloud Run, where a CRON job regularly triggers the service to run on the 2nd-last day of every month. The necessary parameters are passed in through the service’s API and the pipeline runs sequentially in the background for ALL our clients, uploading their reports directly to the staging ground without human intervention. This helps save valuable time and also reduces the likelihood of copying errors being introduced in the final reports.
Additionally, a Slack Messenger service furnishes internal updates on the status of each report, such as fetching-stage data, any error messages, backtraces, and notifies when a report is ready for review.
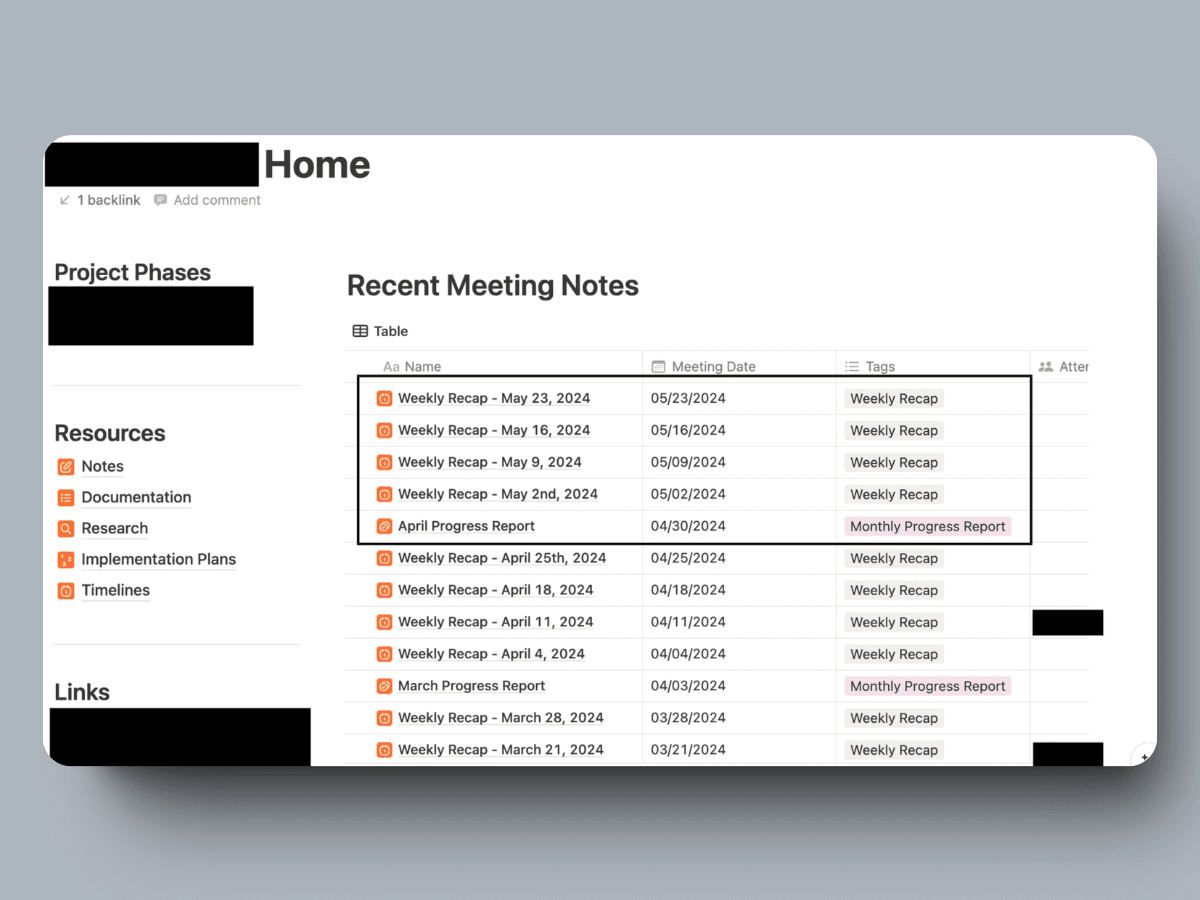
4+1 documents that will be fetched from the client’s portal in Notion. (stage 1)

The Monthly Progress Report uploaded to the intermediate database. (stage 3)

Our slack messaging system providing key information on fetching and completion status.